Crescent - dataframe library in C23 built using safe_c.h and cforge
This article contains a lot of images, if your browser failed to load them, try a different browser. Firefox based browsers looks to have issues loading the images.
Another note: it is a very long article, I was thinking of splitting it but this bearblog account is my documentation medium anyway, so I apologize in advance for readers getting annoyed at the length of this article.
Introduction - Building a Pandas Replacement in modern C23
I've been maintaining a side project called valueHunter ~ a screener for stock markets, used as internal tool for office work. It loads about 970 stocks, runs four screening strategies (undervalued growth, deep value, safe tech, composite), then does about 14 DataFrame analytics operations on the result. Basically a small data pipeline.
The original version was Python with Pandas. It worked fine, but for someone used to work with low level languages, Python dataframe libraries such as Pandas and Polars left me looking for more speed. Added that I'd been wanting to build something finance-related project in modern C23 for a while, so one weekend I thought: "let me just build my own dataframe in C23." After all I've been building quite a lot of my internal tools in C, Zig and Rust. Well, let's just say that weekend (around 4 months ago) turned into a rabbit hole. I ended up with a custom DataFrame library called Crescent, built using my own custom build system (cforge), while implementing safe_c.h standard as the header file, and even though the performance result is kinda expected, but still it surprised me.
The Numbers First
Three libraries, one pipeline, four data sizes. The same code path: load CSV → 4 screening strategies → 14 DataFrame operations. All produce identical output.
Small data (970 rows, 430 KB)

That's ~49x faster than Pandas and ~32x faster than Python/Polars (Python numbers from prior measurement, marked ††).
But fast at 970 rows is expected. What matters is how it scales.
Scaling to 1.9 million rows (866 MB)

Resource breakdown by dataset
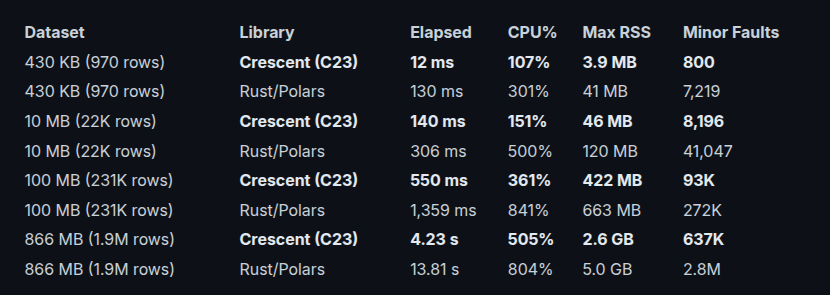
Crescent wins at every size. On small data it dominates (10.8x faster than Rust). On large data it still leads ~ 3.3x faster at 1.9M rows, using 505% CPU (up from 107% at small sizes) and 2.6 GB RAM vs Rust's 5.0 GB. Rust burns 300-800% CPU between the smallest and largest data sizes ~ average 2-3x more cores for a slower result.
At 1.9M rows, Crescent uses half the RAM and much less CPU compared to Rust/Polars while running faster.
The question everyone asks: "what about a real-time webapp?" The C binary processes the full pipeline in 12 ms. Rust takes 130 ms. Python takes 400+ ms. For a webapp endpoint called on every page load, 12 ms vs 130 ms is the difference between "instantly" and "noticeable lag."
Wait, Isn't C Supposed to Be Hard?
Yes and No. With the tools available in modern C, it's less hard than it used to be. Here's how Crescent works.
The setup has three layers:
Layer 1: safe_c.h ~ the utility belt
Read more on safe_c.h here
safe_c.h is a single-header C library that adds things C should have had from the start:
- RAII macros via
__attribute__((cleanup))~ resources auto-clean when they go out of scope - Type-safe vectors via
DEFINE_VECTOR_TYPE(name, type)~ basically generics for dynamic arrays - Result/Optional types ~
Result<T, Error>monads without the ceremony - StringView, Span, smart pointers ~ stuff you'd recognize from Rust or C++
Here's what it looks like in practice:
// File auto-closes when scope exits
{
AUTO_FILE(f, "data.csv", "r");
// use f...
} // fclose() called automatically
// Vector with typed API
DEFINE_VECTOR_TYPE(Stock, Stock)
StockVector vec; // vec.data, vec.size, vec.capacity
Stock_vector_init(&vec);
Stock_vector_push(&vec, my_stock);
Stock_vector_free(&vec); // or let AUTO_TYPED_VECTOR handle it
The AUTO_DataFrame, AUTO_Dsl, AUTO_DFQ_SCOPE macros you'll see later are all built on safe_c.h's CLEANUP mechanism. Without it, every single error path would need manual goto cleanup boilerplate. With it, the code looks almost as clean as Python.
Layer 2: Crescent ~ the DataFrame library
Crescent or libvh_df is the core of this project. It's a pure-C DataFrame library (~10,000 lines of code) that implements:
- Columnar storage (f32, f64, i32, i64, str, dictionary-encoded str)
- CSV reader (multi-threaded, RFC-4180 compliant, bump-arena allocation ~ zero heap per row)
- SIMD aggregations (sum, min, max with AVX2)
- GroupBy, aggregate, window rank, rolling windows
- Pivot tables, merge/join, melt
- Correlation matrix, z-score, binning (cut), describe, value counts
- String operations (contains, startswith, endswith, lower, upper)
- A chainable DSL for building pipelines
The DSL is the part that makes it usable. Here's a value-quality screen:
AUTO_DFQ_SCOPE(dfs, q, out);
q = dfq_from_frame(base);
dfq_query(q, "per > 0 AND roe > 0.08 AND pbv > 0 AND der < 1.5 AND month > -0.10");
dfq_rank(q, "sector", "per", "sector_per_rank", true);
dfq_sort_asc(q, "per");
dfq_head(q, 20);
dfq_assign_mul_scalar(q, "ROE%", "roe", 100.0f);
dfq_assign_mul_scalar(q, "Month%", "month", 100.0f);
DFQ_SELECT(q, "code", "stock", "sector", "per", "ROE%", "der", "Month%", "sector_per_rank");
DFQ_END(q, out);
And the equivalent in Pandas:
result = (
df.query("PER > 0 and `ROE %` > 0.08 and PBV > 0 and DER < 1.5 and Month > -0.10")
.assign(
sector_per_rank=lambda x: x.groupby('Sector')['PER'].rank().astype(int),
**{
'ROE%': lambda x: x['ROE %'] * 100,
'Month%': lambda x: x['Month'] * 100,
}
)
.sort_values('PER')
.head(20)[['Code', 'Stock', 'Sector', 'PER', 'ROE%', 'DER', 'Month%', 'sector_per_rank']]
)
You still need AUTO_DFQ_SCOPE, dfq_from_frame, and DFQ_END around the edges. But the middle reads like Pandas. dfq_assign_mul_scalar replaces the old dfq_assign_scalar(q, "ROE%", "roe", VHDF_BINOP_MUL, 100.0f) ~ same work, none of the enum noise. Top to bottom, it flows like a method chain.
The biggest friction point was arithmetic expressions. Before the current version, computing a momentum score looked like:
dfq_assign_scalar(q, "_w_week", "week", VHDF_BINOP_MUL, 0.10f);
dfq_assign_scalar(q, "_w_month", "month", VHDF_BINOP_MUL, 0.40f);
dfq_assign_scalar(q, "_w_3mo", "f_3_0mo", VHDF_BINOP_MUL, 0.30f);
dfq_assign_scalar(q, "_w_ytd", "ytd", VHDF_BINOP_MUL, 0.20f);
dfq_assign(q, "_t1", "_w_week", VHDF_BINOP_ADD, "_w_month");
dfq_assign(q, "_t2", "_w_3mo", VHDF_BINOP_ADD, "_w_ytd");
dfq_assign(q, "momentum_score", "_t1", VHDF_BINOP_ADD, "_t2");
Seven calls for one formula. That's where I added dfq_assign_expr, a tiny recursive-descent expression parser built into the DSL:
dfq_assign_expr(q, "momentum_score", "week*0.10 + month*0.40 + f_3_0mo*0.30 + ytd*0.20");
One call. The parser handles +, -, *, /, parentheses, and proper precedence. Under the hood it builds the same temporary columns as the manual version, then tears them down automatically. You never see the scaffolding.
Beyond dfq_assign_expr, the DSL now includes purpose-built shortcuts that a typical screener function is now six readable lines:
DataFrame* screen_safe_tech(const DataFrame *base) {
AUTO_Dsl(q);
q = dfq_from_frame(base);
dfq_and_where_str_eq(q, "sector", "Technology");
dfq_and_where_gt(q, "roe", 0.15f);
dfq_and_where_gt(q, "npm", 0.10f);
dfq_and_where_lt(q, "der", 0.80f);
return vhdf_collect_or_null(q);
}
Line by line, that reads like a Pandas boolean mask.
The Pandas equivalent is:
df[
(df['Sector'] == 'Technology') &
(df['ROE %'] > 0.15) &
(df['NPM'] > 0.10) &
(df['DER'] < 0.80)
]
Layer 3: cforge ~ the build system
Read more on cforge here
cforge is part build tool, part code generator, and part linter. The important part for Crescent is that it removes the repetitive C glue around schemas, dataframe adapters, and reflection.
Three commands handle everything:
cforge gen-struct <csv> <Name>
Reads your CSV file, samples ~100 rows, and infers C types for each column by examining actual values:
- Integer within
i32range (~±2 billion) →i32; larger →i64; overflow →char* - Float (contains
.) →f32 "true"/"false"→bool- Everything else →
char*
Type conflicts resolve by widening ~ int -> float -> string. Column names are sanitized: lowercase, non-alphanumeric characters replaced with _, and C keyword collisions get an f_ prefix.
Output: include/<name>_auto.h, containing a typed C struct that matches the CSV plus the small helper macros and vector boilerplate needed to use it.
The implementation template lives in include/csv_to_struct_py.h, but the relevant part for day-to-day work is simple: point it at a CSV and you get a usable C struct instead of writing one by hand.
After generation, gen-struct automatically chains into gen-df-col ~ you don't need to run both commands separately.
cforge gen-df-col <Name>
Reads include/<name>_auto.h and emits the dataframe adapter layer:
include/dataframe_col.hsrc/dataframe_col.cinclude/core.h+src/core.c
This is the code that wires a typed row schema into Crescent's columnar frame representation and CSV ingest path. In practice it means I do not hand-write 50+ column append calls or schema setup code. The implementation template lives in include/gen_df_col_py.h.
cforge reflect
Generates the reflection and serialization glue into generated_reflection.c and generated_macros.h. That covers the boring support code around things like cloning, printing, CSV/JSON conversion, field metadata, and typed access helpers. The implementation template lives in include/reflection_generator_py.h.
Auto-generation does the heavy lifting for C. The schema glue, reflection helpers, and CSV integration are generated; the human writes the actual pipeline and application logic. That is a large part of why Crescent is practical to build in C at all.
The Three-Stage Build
cforge build main
This generates a build/dynamic_dev.mk Makefile and runs three stages:
Stage 1 ~ Static Analysis:
gcc -std=c23 -fanalyzer -Wall -Wextra -Wpedantic -Wconversion -Wshadow \
-Wformat=2 -Wimplicit-fallthrough -D_POSIX_C_SOURCE=202308L
The -fanalyzer flag runs GCC's static analyzer on every compilation unit. Catches null dereferences, use-after-free, buffer overflows, and double-free at compile time. Objects go to build/objs_ana/.
Stage 2 ~ Sanitizer:
gcc -ggdb -fno-omit-frame-pointer -fsanitize=address,undefined
Builds with AddressSanitizer (ASAN) and UndefinedBehaviorSanitizer (UBSAN). After linking, cforge executes the binary with a 5-second timeout. If the sanitizer catches a heap buffer overflow, use-after-free, or integer overflow, the binary crashes with a stack trace pointing to the exact file and line. The release build does not proceed until the sanitizer passes. Objects go to build/objs_san/.
Stage 3 ~ Release:
gcc -O2 -march=native -D_FORTIFY_SOURCE=3 -fstack-protector-strong \
-fstack-clash-protection -fcf-protection=full \
-fstrict-flex-arrays=3 -fno-plt -fno-math-errno -fno-trapping-math \
-fPIE -pie -Wl,-z,relro,-z,now
Full hardened release: buffer overflow detection (FORTIFY_SOURCE=3), stack canaries, stack-clash protection, control-flow integrity (CET shadow stack), hardened linker relocations (-z relro,now), PIE for ASLR. Output: build/main. Objects go to build/objs_rel/.
Note: the Release stage only use -O2, not -O3 as the most aggressive optimization
Incremental compilation is handled by SHA-256 hashing: each .c file gets its hash stored in build/.hash_<path>. On the next run, if a source file's hash hasn't changed, its .o is reused across all three stages. Changing a single file triggers recompilation of only that file ~ typically under 1 second. -MMD -MP generates Make dependency files so header changes propagate correctly.
Why all these hassle, you might ask? Correctness and safety is super important in finance (my main domain), hence I'm applying what's been the standard in libc++ and some more. You can read about libc++ here
Thousands of bugs squashed, 30% drop in baseline segfault rate, out-of-bounds access, UB-triggering precondition violation. All these at 0.3% performance cost at most. It's a no-brainer option, you'd be crazy if you don't use this.
Syntax Comparison: Same Logic, Three Languages
Here's how the same operation looks in each:
Filter + Sort + Head
Pandas:
result = (
df
.query("PER > 0 and `ROE %` > 0.08 and PBV > 0 and DER < 1.5 and Month > -0.10")
.assign(sector_per_rank=lambda x: (
x.groupby('Sector')['PER']
.rank()
.astype(int)
))
.sort_values('PER')
.head(20)
)
Crescent (C DSL):
AUTO_DFQ_SCOPE(dfs, q, out);
q = dfq_from_frame(base);
dfq_query(q, "per > 0 AND roe > 0.08 AND pbv > 0 AND der < 1.5 AND month > -0.10");
dfq_rank(q, "sector", "per", "sector_per_rank", true);
dfq_sort_asc(q, "per");
dfq_head(q, 20);
dfq_assign_mul_scalar(q, "ROE%", "roe", 100.0f);
dfq_assign_mul_scalar(q, "Month%", "month", 100.0f);
DFQ_SELECT(q, "code", "stock", "sector", "per", "ROE%", "der", "Month%", "sector_per_rank");
DFQ_END(q, out);
If you want the performance-first form, Crescent also offers typed helpers that skip the string parser (dfq_query) entirely:
dfq_and_where_gt(q, "per", 0.0f);
dfq_and_where_gt(q, "roe", 0.08f);
dfq_and_where_gt(q, "pbv", 0.0f);
dfq_and_where_lt(q, "der", 1.5f);
dfq_and_where_gt(q, "month", -0.10f);
For pure numeric AND filters both paths land on the same fused predicate-execution engine. The typed version avoids parsing, trimming, and token conversion, but on large frames the scan dominates and the gap is small. Use dfq_query(...) when mirroring Pandas .query(...) examples, and dfq_and_where_* / dfq_or_where_* when you want the typed C-native surface.
Polars via Rust:
let result = base.clone().lazy()
.filter(
col("PER").gt(lit(0.0))
.and(col("ROE %").gt(lit(0.08)))
.and(col("PBV").gt(lit(0.0)))
.and(col("DER").lt(lit(1.5)))
.and(col("Month").gt(lit(-0.10))),
)
.with_columns([
col("PER")
.rank(
RankOptions {
method: RankMethod::Ordinal,
descending: false,
},
None,
)
.over([col("Sector")])
.alias("sector_per_rank"),
])
.sort(["PER"], Default::default())
.limit(20)
.collect()?;
Filter + Top-K + CSV export
This is the same workflow as the "export top value picks" block in valueHunter.
Pandas:
value_picks = (
df[df['PER']
.between(0.01, 15.0)
& (df['ROE %'] > 0.08)
& (df['DER'] < 1.5)]
.nsmallest(20, 'PER')
)
value_picks.to_csv('value_picks_pandas.csv', index=False)
Crescent (C DSL):
AUTO_DFQ_SCOPE(dfs14, q14, export14);
q14 = dfq_from_frame(base);
dfq_and_where_between(q14, "per", 0.01f, 15.0f);
dfq_and_where_gt(q14, "roe", 0.08f);
dfq_and_where_lt(q14, "der", 1.5f);
dfq_nsmallest(q14, 20, "per");
DFQ_SELECT(q14, "code", "stock", "sector", "per", "per_rank", "Momentum_Score", "roe", "der");
/* Materialise once; use the frame for both CSV export and display. */
DFQ_END(q14, export14);
if (export14) {
if (vhdf_frame_to_csv(export14, "value_picks.csv"))
printf("\n[Export] Wrote %zu value picks to value_picks.csv\n",
export14->num_rows);
}
Polars via Rust:
let value_picks = base.clone().lazy()
.filter(
col("PER").gt_eq(lit(0.01))
.and(col("PER").lt_eq(lit(15.0)))
.and(col("ROE %").gt(lit(0.08)))
.and(col("DER").lt(lit(1.5))),
)
.sort(["PER"], Default::default())
.limit(20)
.collect()?;
let mut file = std::fs::File::create("value_picks_polars.csv")?;
CsvWriter::new(&mut file).finish(&mut value_picks.clone())?;
The performance story here is the same as the previous example: the typed dfq_and_where_* filters are the faster C-side surface, because they go straight into the deferred/fused numeric predicate path. A dfq_query(...) version would still be valid, but it would pay a small extra parsing cost up front for no gain in the actual filter execution.
Pandas is the shortest. Crescent is explicit but still compact. Rust/Polars is serviceable, but once CSV export enters the picture the chain expands into extra builder and I/O ceremony.
Computed Column
Pandas:
df['Momentum_Score'] = (
df['Week']*0.10 +
df['Month']*0.40 +
df['3.0Mo']*0.30 +
df['YTD']*0.20
)
Crescent (C DSL):
dfq_assign_expr(q, "momentum_score",
"week*0.10 + month*0.40 + f_3_0mo*0.30 + ytd*0.20");
One call. The parser handles +, -, *, /, parentheses, and proper precedence. Under the hood it builds the same temporary columns as the manual version, then tears them down automatically. You never see the scaffolding.
Polars via Rust:
.with_columns([(
col("Week") * lit(0.10)
+ col("Month") * lit(0.40)
+ col("3.0Mo") * lit(0.30)
+ col("YTD") * lit(0.20)
).alias("Momentum_Score")])
Pandas and C are one-liners. Rust requires lit() wrapping every scalar and explicit .alias().
GroupBy + Aggregate
Pandas:
df.groupby('Sector')['PER'].mean().rename('avg_per').reset_index()
Crescent (C DSL):
dfq_groupby(q, "sector");
dfq_groupby_mean(q, "per", "avg_per");
Polars via Rust:
.group_by(vec![col("Sector")]).agg([col("PER").mean().alias("avg_per")])
ISIN filter
Pandas:
df[df.Sector.isin(['Finance', 'Technology'])]
Crescent (C DSL):
DFQ_ISIN(q, "sector", "Finance", "Technology");
Polars via Rust:
.filter(col("Sector").eq(lit("Finance")).or(col("Sector").eq(lit("Technology"))))
No native is_in for the C DSL ~ just a variadic macro. Rust/Polars requires chaining .eq().or().eq() for simple membership checks.
The Verdict on Syntax
Ranking each on compactness and clarity:

Pandas is still the clearest and most compact. Fifteen years of refinement shows. But the C DSL has closed a lot of that gap.
Crescent (C23) is now genuinely approachable. dfq_and_where_gt(q, "roe", 0.15f) reads like a Pandas boolean mask; dfq_or_where_gt(...) gives the matching OR form when you need it. dfq_groupby_mean(q, "per", "avg_per") self-documents the operation ~ no enum values to memorize. DFQ_SORT(q, VHDF_DESC("sector_score"), VHDF_DESC("value_score")) reads as clearly as .sort_values(by=['sector_score','value_score'], ascending=False). The VHDF_BINOP_* enums that used to litter every arithmetic call are now hidden behind purpose-built shortcuts.
The remaining gap is the scaffolding: AUTO_DFQ_SCOPE, dfq_from_frame, DFQ_END add ~3 lines per pipeline. And the mutable builder means you can't chain operations like Pandas ~ each is a separate statement. But once you know the RAII scope pattern (about 5 minutes of learning), the DSL reads top-to-bottom like a method chain.
Rust/Polars is the most verbose. Every operation requires ceremony: lit() wrapping every scalar, RankOptions { method: RankMethod::Ordinal, descending: false } for a sort direction, .clone().lazy() and .collect() on every chain, .alias() for every column rename. The type system does catch real bugs at compile time. But the API fights you on simple things. A rank call in C takes four positional arguments. In Rust it's a struct + enum + method chain. You'll need a few hours before it feels natural.
Bottom line: Pandas is the most intuitive. The C DSL is the most surprising ~ it shouldn't be this readable for C, but it is. A Pandas developer can read a Crescent screener and understand every line without explanation. Rust/Polars gets the job done but makes you work for it.
Memory
Pandas uses about 110 MB for the small dataset (970 rows). Crescent uses 2-4 MB. The difference comes down to:
- Bump arena allocation ~ the CSV parser allocates one large arena (~128 KB stack buffer + linked slabs for overflow) and doles out memory linearly. No per-field
malloc. Freeing is a single arena reset. - Columnar storage ~ float arrays are contiguous
float*blocks, not arrays of Python objects with refcounting overhead. - No interpreter ~ no Python object overhead per value (28+ bytes per Python float vs 4 bytes per C float).
- No GC ~ deterministic allocation, no collection pauses. The pattern is "allocate arena, process, free arena".
Where the speed comes from
The ~49x speedup (vs Pandas) isn't from one thing. It's a stack of small wins:
Multi-threaded CSV parsing ~ Crescent splits the file into chunks, parses each chunk on a separate thread, then merges. The CSV parser itself is RFC-4180 compliant with quote escaping, arena allocation, and zero heap allocations per field. Pandas parses CSV on a single thread.
Memory locality ~ Columnar storage means all ROE values sit in a contiguous
float*array. Afilter(roe > 0.15)touches one cache line per 16 values. Row-oriented storage (Python list of tuples) scatters values across memory.No refcounting ~ Every Python float access increments and decrements a reference count. Over 970 rows × 50 columns × multiple operations, this dominates the profile. Pandas user CPU is 2.48 s for 0.59 s wall time ~ it's saturating over 4 cores with refcounting and GC overhead.
Rust/Polars: The Blazingly Mediocre Part
After seeing Crescent hit 12 ms, I thought: "Okay, but what if we just use Polars from Rust directly? No Python, no GIL, no FFI ~ pure native speed." I rewrote the entire screener in Rust using polars 0.53. Identical output, 55 columns, same data to the last decimal.
Here's the full picture across all data sizes:
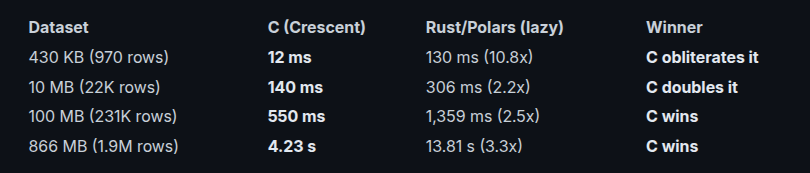
Rust/Polars loses at every data size. There is no crossover point where it catches up. The professional, native-compiled, battle-tested DataFrame library loses to a side-project C program on small data (10.8x), medium data (2.2x), and large data (3.3x).
The resource comparison at 1.9M rows:
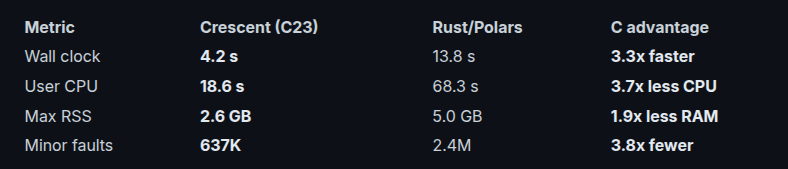
The numbers are clear: at 970 rows Crescent finishes in 12 ms while Rust/Polars takes 130 ms. At 1.9M rows it's 4.2 s versus 13.81 s. Rust is not the bottleneck here ~ the architecture is.
Crescent stores floats as plain float*: a pointer and a length. No Arrow buffers, no null bitmaps, no offset tables, no buffer metadata. When a filter says roe > 0.15, it generates a tight loop over a contiguous array. The compiler vectorizes it, the prefetcher keeps up, and the result is a stream of indices. CPU usage stays low: 107% at small data, 505% at 1.9M rows.
Polars uses Arrow-backed columns where every access traverses buffer metadata, null bitmaps, and offset tables. For 970 rows, the query optimizer's cost model alone takes more time than the actual filter work. Polars CPU usage hits 301% on small data and 804% at 1.9M rows ~ nearly 3x more cores on average for a slower result. The abstractions are sound in general, but at this scale they add indirection without delivering compensating speed.
What went wrong?
Polars brought a query optimizer, Arrow buffers, and a thread pool to a street fight. For 970 rows, the optimizer's cost model takes more time than the actual filter. For 1.9M rows, Arrow's buffer metadata, null bitmaps, and offset tables add indirection that C's raw float* arrays don't have.
Crescent stores floats as float*. No bitmaps, no metadata, no indirection. Just a pointer and a length. When a filter says roe > 0.15, it generates a loop over a contiguous float array. No null checks, no offset calculation, no buffer traversal. The compiler vectorizes it, the prefetcher keeps up, and the result is a stream of passing indices.
Polars' Arrow-backed columns add indirection at every access. For small data, the overhead is negligible. For medium data, it starts to add up. For large data, the optimizer and parallelism usually compensate ~ but not enough to catch Crescent.
Why no benchmark with larger dataset? Actually it was Polars in Rust that stopped me doing that, since using the 866MB csv file stutters my system heavily, up to the point I need to close down my other apps / browsers...quite embarrassing if you ask me, Crescent in C23 did not have this issue, I can use my system just fine while doing the benches. Now imagine what a 5-10GB file would do to Polars in Rust.
I often do benches in both quiet and noisy system, in my use case the noisy test is more relevant since I'm using my machine not only for writing programs, but also monitoring the stock markets, entering algorithm trades, running several data scraping bots. Here's what I wrote in my cgrep article:
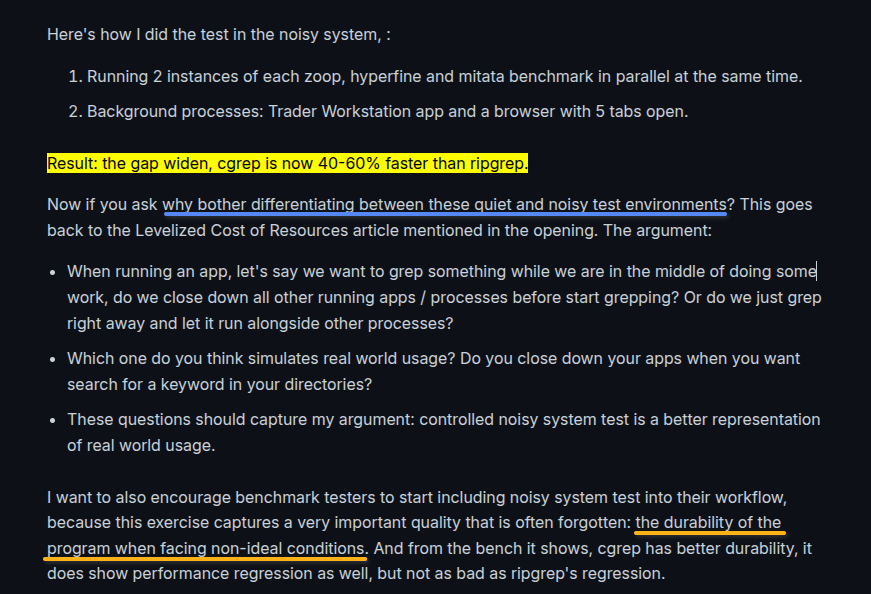
So, do you close your other apps when you're running a program? Or do you keep other apps running? Exactly my point! Too many benchmarks do not consider the durability of a program, I think controlled noisy bench should be the normal.
Is Rust/Polars ever faster?
At no data size tested (430 KB to 866 MB) did Rust/Polars beat Crescent. The gap narrows at 10 MB (2.2x) but widens again at larger sizes (3.3x at 1.9M rows) as Crescent's multi-threaded operations scale with data.
Under the Hood: Why Crescent's engine is faster
Let's do a deep dive into Crescent's design, you'll see why putting time into application architecture is super worth it. Crescent wins because the execution engine is tuned for a very specific shape of workload: dense numeric columns, repeated fixed-schema pipelines, low-cardinality categorical strings, and a DSL that carries row selections around as index views instead of copying whole frames after every step.
Polars is solving a broader problem. It supports Arrow semantics, null bitmaps, chunked arrays, lazy planning, type coercion, streaming execution, and a much more general optimizer surface. Crescent solves a narrower problem and exploits that narrowness aggressively.
How the Crescent engine does it:
1. The DSL is view-first, not frame-first
dfq_from_frame() does not clone the input frame. It starts with:
source = frameview = NULLmeaning "full-range sentinel"view_n = frame->num_rows
Most pipeline steps operate on an index view, not on copied columns. A filter is usually just shrinking a size_t row-index vector.
The key mechanism is deferred predicate fusion:
dfq_and_where_gt()/dfq_and_where_lt()end up indfq_filter()dfq_filter()does not execute immediately; it appends aPendingPredintodsl->pending_predsdfq_flush_pending()executes the entireANDchain in one fused pass
So this:
dfq_and_where_gt(q, "per", 0.0f);
dfq_and_where_gt(q, "roe", 0.08f);
dfq_and_where_lt(q, "der", 1.5f);
does not run three full dataframe filters. It compiles into one tight kernel over the active row set. Each worker gets a pointer to the source frame, the current view, a slice of rows, the full PendingPred[] array, and a local output buffer of passing indices. fused_filter_worker() evaluates all predicates for each row before deciding whether to push that row index. The engine only allocates the final surviving row-index vector once.
This is a very different cost model from "evaluate expression node A, materialize, then B, materialize, then C."
2. Projection stays shallow for as long as possible
Older dataframe libraries often lose performance by turning metadata operations into data copies. Crescent avoids that in the fast path: vhdf_select_columns() aliases columns instead of copying them. vhdf_drop_columns() aliases the kept columns. vhdf_rename_columns() aliases the same backing storage with a different column name.
The implementation uses refcounted column aliasing through vhdf_column_alias(), shared_from, and ref_count. In practice, select, drop, and rename are mostly metadata edits plus a reference-count bump.
The DSL's projection pushdown keeps that advantage alive. dfq_select() can project the source first and only apply the row view afterward through dfq_project_source_view(). If the final report only prints 6 columns, Crescent tries hard not to drag 55 columns through the last materialization step.
This is one of the biggest reasons the valueHunter pipelines (Crescent's project implementation) stay fast.
3. Materialization is index-gather, and it is parallel
Eventually some operations do need a real frame. When that happens, Crescent materializes through vhdf_frame_take_indices().
It avoids row-by-row append loops. Instead it works in two phases: allocate destination columns up front at the exact required row count, then gather selected rows into those columns. The gather parallelizes across columns when the problem size is large enough.
For numeric columns on x86, the gather path uses AVX2 helpers where available. For large outputs, Crescent spreads the gather work over multiple threads. For string columns it gathers pointers, not heap-allocated string objects. The destination frame retains the source StringArena, so the gather does not duplicate string payloads.
This makes "filter -> collect" much cheaper than a generic deep-copy materializer.
4. Top-k avoids full sort whenever the query only needs top-k
This is a big one in finance workloads.
If the pipeline asks for:
dfq_nsmallest(q, 20, "per");
Crescent does not sort the full active dataset unless it has to. dfq_nsmallest() goes through dfq_topk():
- build
(value, original_idx)pairs - do multi-threaded pair extraction for large views
- run
vhdf_select_topk()to partition/select the bestk - sort only those
kpairs for final presentation
So the cost is closer to O(n) selection plus O(k log k) final ordering, not O(n log n) full sort.
This is the right trade for screener-style outputs where the user wants "best 20 by PER", not "fully sorted 1.9 million row frame."
5. String handling is designed around pointer identity and dictionary codes
Crescent keeps string overhead low by treating them as interned pointers rather than general heap objects.
During CSV ingest, strings go into a StringArena. Two things happen: repeated equal strings often collapse to the same pointer, and string lifetime becomes arena lifetime instead of per-cell lifetime. This lets several operations use pointer identity as a fast-path before falling back to strcmp.
After ingest, vhdf_frame_auto_dict_encode() can convert low-cardinality string columns from VHDF_COL_STR to VHDF_COL_DICT_STR:
- one
u32 *codesarray per column - one
const char **dictarray of unique values
From there sector == "Technology" becomes integer-code comparison. isin over categorical columns becomes code-set membership. Group keys become much cheaper to hash and compare.
For valueHunter, columns like sector, industry, and mc_class are exactly the shape where this pays off.
6. CSV ingestion is built for fixed-schema throughput, not generic row objects
The CSV path is one of Crescent's least glamorous but most important wins.
The engine does several things that matter: pread()-based chunking instead of a mutex-serialized read() loop, pre-planned chunk boundaries before worker execution, quote-free fast path with edge-only boundary scanning, SIMD helpers for record boundary detection and comma splitting, 2 MiB-aligned worker buffers, one StringArena per worker reused across chunks, and row-count hints pushed into the schema adapter so columns can reserve near-final capacity immediately.
The field-adapter path means the parser writes directly into dataframe columns. There is no intermediate struct Row, no boxed scalar representation, and no "parse into temporary rows, then convert rows into columns" phase.
This is a major reason Crescent wins both wall time and RSS on the large CSV runs.
7. The numeric representation is deliberately narrow
Most of the stock-screener numeric columns are stored as f32, not f64.
So: half the bandwidth, twice as many values per cache line, lower gather/scatter cost, and lower RSS pressure through the whole pipeline.
I made this choice because the domain allows it. For this workload, single-precision is enough. Crescent takes the win instead of paying for double precision everywhere "just in case."
This compounds with the other choices: contiguous float *, no Python object headers, no refcounts, no validity bitmap checks in the dense fast path, and fewer bytes touched per row during filter, rank, sort, and top-k.
8. SIMD is used where the loops are actually hot
There is more SIMD in Crescent than the earlier summary makes obvious.
I did not try to vectorize everything. I targeted the loops that show up over and over in dataframe workloads:
- numeric reductions
- numeric filters
- element-wise arithmetic
- correlation
- gather/materialization
- CSV structural scanning
On x86, the implementation uses runtime dispatch with __builtin_cpu_supports(...) and function-level __attribute__((target(...))) specializations. That means the same binary can:
- run AVX2 kernels when the CPU has AVX2
- use AVX2+FMA for correlation
- use AVX-512 for parts of the CSV scanner when available
- fall back to scalar code everywhere else
So the fast path is opportunistic, not mandatory.
Reductions
The obvious starting point is reductions:
vhdf_sum_f32_avx2()vhdf_min_f32_avx2()vhdf_max_f32_avx2()vhdf_sum_i32_avx2()vhdf_min_i32_avx2()vhdf_max_i32_avx2()
These work directly on contiguous typed arrays:
- 8
f32lanes at a time with__m256 - 8
i32lanes at a time with__m256i
For i32 sum, Crescent widens to i64 immediately with _mm256_cvtepi32_epi64(), so the SIMD accumulator does not overflow on long scans. That detail matters. It is the difference between a benchmark kernel and something I can use in a real dataframe engine.
Filters
The SIMD filter path is more important than the reduction path.
The kernels:
filter_f32_avx2()filter_f64_avx2()filter_i32_avx2()
do not build a boolean mask array and compact it later. They:
- load a vector of values
- compare against a broadcast threshold
- turn the compare result into a bitmask with
movemask - walk the set bits with
ctz - write passing row indices directly into the output index buffer
That matches Crescent's engine design perfectly. The natural output of a filter in Crescent is not another column or another bitmap. It is a compact row-index list that the DSL can carry forward as the active view.
So the SIMD path is doing two useful things at once:
- faster comparisons per iteration
- no extra pass to convert booleans into row indices
Element-wise arithmetic
The same pattern shows up in the arithmetic helpers:
vhdf_scalar_op_f32_avx2()vhdf_binary_op_f32_avx2()vhdf_clip_f32_avx2()vhdf_diff1_f32_avx2()
These are the kernels behind operations like:
- multiply a column by a scalar
- add or subtract two columns
- compute first differences
- clip values into a range
Because the numeric columns are plain float * arrays, the loop is just "load eight floats, apply the op, store eight floats." There is no per-element dispatch and no object layer in the middle.
Correlation uses FMA
The correlation path is one of the more technical SIMD kernels.
Crescent has a dense f32 fast path:
has_nan_f32_avx2()first checks whether either input contains NaNs- if not,
vhdf_col_corr_f32_fma()computes Pearson correlation with AVX2+FMA
The implementation is split deliberately:
- the means are accumulated with widened
f64sums - covariance and variance are accumulated with
_mm256_fmadd_ps
So the hot inner loop gets fused multiply-add while the mean computation keeps better numerical behavior than naive f32 accumulation.
That is not a general-purpose linear algebra engine. It is a targeted statistics kernel for the dataframe operations I actually run.
Gather is vectorized too
One easy thing to miss is that Crescent also vectorizes part of materialization.
When a filtered frame finally has to become a real dense frame, vhdf_frame_take_indices() uses:
gather_f32_avx2()gather_f64_avx2()
under the hood for numeric columns, via _mm256_i32gather_ps() and _mm256_i32gather_pd().
So Crescent is not only fast at contiguous scans. It also accelerates the next bottleneck that usually appears after filtering gets cheap: gathering selected rows back into dense columns.
The CSV parser uses SIMD too
Some of the CSV speedup is from multithreading and arenas, but not all of it. The parser also uses AVX2 and AVX-512 for structural scanning:
vhdf_mem_has_byte_*()checks whether a chunk contains quotes or delimitersvhdf_find_next_newline_*()finds newlines quicklyvhdf_csv_record_len_structural_*()finds record boundaries while respecting quoted newlinesvhdf_csv_split_fields_noquote_*()finds comma positions in quote-free rows
These kernels scan 32 or 64 bytes at a time, build masks, then use bit scans to locate the interesting byte positions.
That is exactly the kind of work SIMD is good at:
- delimiter detection
- quote detection
- structural scanning before the parser drops into scalar cleanup logic
So when Crescent wins on CSV load time, it is not just "threads plus arenas." It is also using vector instructions to reduce the byte-scanning cost before field conversion even starts.
Why SIMD pays off here
SIMD only helps if the surrounding engine lets it stay close to the real bottleneck.
Crescent's layout makes that possible:
- dense homogeneous arrays
- low per-element metadata cost
- no validity bitmap in the common dense path
- row-index outputs from filters instead of heavyweight intermediate objects
- fewer abstraction layers between the DSL call and the hot loop
That means the vector kernels are doing actual data work instead of spending half their time navigating metadata.
9. Threading is conservative on small data and aggressive on large data
One reason Crescent does so well at 970 rows is that it avoids acting like a distributed systems project for a toy dataset.
Examples:
dfq_flush_pending()stays single-threaded below 4096 active rows- gather materialization only goes multi-threaded when
num_columns * num_rowscrosses a threshold - sort parallelism is only enabled for large enough views
dfq_from_frame()scales the compute thread count from the in-memory frame size instead of blindly using all cores
So Crescent avoids paying thread-pool and scheduling overhead when the data is tiny, but it still fans out once the frame is large enough for the extra coordination to amortize. This design choice is often forgotten, amateurish mindset would instead do "put the pedal to the metal" mentality ~ meaning using every single cores available in a system.
This is exactly how my cgrep managed to beat ripgrep using much less resources (especially RAM). You can read about cgrep here.
This explains a lot of why the 970-row case is absurdly fast while the 1.9M-row case still scales.
10. This benchmark fits Crescent's fast path unusually well
This is also where I need to be honest.
Crescent wins here because this benchmark sits right in its sweet spot: dense numeric columns, a fixed schema, the same pipeline run repeatedly, mostly non-null data, low-cardinality categorical strings, and top-k outputs rather than arbitrary joins or nested types.
Polars is built for a broader world. It handles nested types, heavy null propagation, ad-hoc expressions, Parquet-first analytics, and large multi-way joins over heterogeneous sources. For those workloads, its abstractions pay for themselves. This workload is not one of them.
This workload is a stock screener with known columns and repeated filters. Crescent is optimized for exactly that.
The gap exists because Crescent's engine simply is more efficient: fewer layers, fewer transient allocations, fewer bytes moved, fewer metadata checks in hot loops, and fewer full-frame materializations. Rust itself is not the bottleneck. The design architecture is..this connects to the early section of what I said about it is worth it to take time to think about program's design.
The benchmark I did was run multiple times (~ not less than 30x) and they always paint the same picture. By running it multiple times, that means the programs were run in a warm cache condition. Here I want to point out Polars' data structure / cache locality / memory management left a lot of things to be desired. The evidence were clear: massive page faults and I/O operations even after running the same program with the same data multiple times one after the other.
Crescent on the other hand, on the second run I/O ops got down to mostly zero comparatively very low page faults ~ implies proper cache locality which in turn implies proper data structure and memory management. Crescent's flat arrays and bump-arena allocator walk fewer pages. Polars' chunked buffers and metadata-heavy columns keep the kernel busy even when the data is already in RAM.
That is the real performance story.
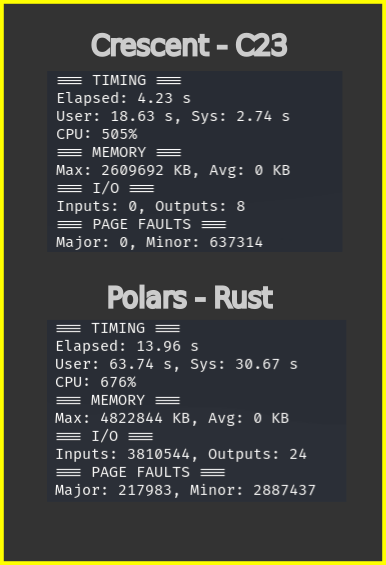 Note: above is a warm-run of the benchmark, note how Crescent is very clean with zero I/O ops and much less Page Faults compared to Polars-Rust, which have loads of I/O ops and Page Faults even on a warm cache.
Note: above is a warm-run of the benchmark, note how Crescent is very clean with zero I/O ops and much less Page Faults compared to Polars-Rust, which have loads of I/O ops and Page Faults even on a warm cache.
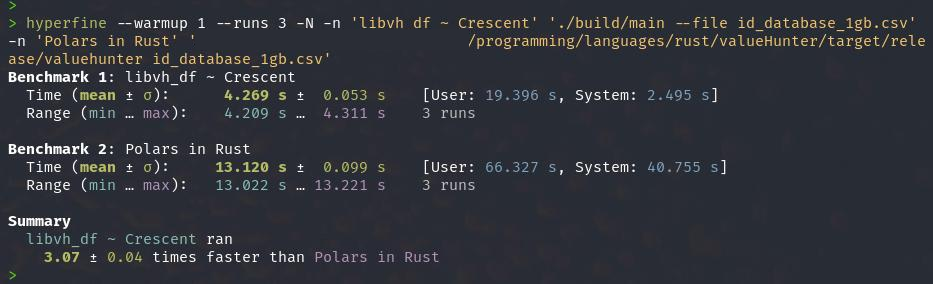
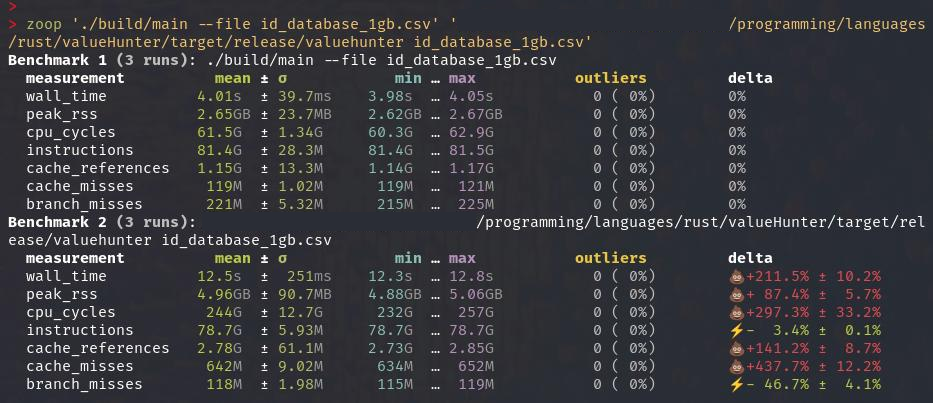
Note on the benchmarks using hyperfine and zoop below, I needed to close all other apps coz Polars would run super slow and the elapsed time would become around 19-20 seconds, compare that to Crescent which has no problem with other apps running. This "embarrassingly parallel" situation is something I often encounter when running Rust programs (ripgrep, polars, when compiling Rust programs) where they burn through lots (if not all) of available cores in order to be "Fast". Blazingly mediocre indeed!
DX on building Crescent
cforge, safe_c.h, and Crescent together make C feel closer to Python than I expected. But "closer" does not mean "the same." The workflow is different, and understanding where it shines and where it fights you matters if you're thinking about doing something similar.
What feels like Python
Auto-generation eliminates the boring parts. I never write struct serialization, CSV adapters, or reflection boilerplate. cforge gen-struct and cforge reflect generate thousands of lines of C I would have otherwise typed by hand. The schema changes, I re-run one command, and the code updates.
Incremental builds are fast. cforge build main hashes every source file with SHA-256. Changing one file triggers recompilation of exactly that file across all three stages ~ typically under one second. The sanitizer stage runs automatically, so I find use-after-free bugs within seconds of introducing them, not in production.
RAII macros remove the cleanup tax. In plain C, every error path needs goto cleanup with a carefully ordered set of frees. With safe_c.h, I declare AUTO_DataFrame(df) and the cleanup happens when the variable goes out of scope. The DSL pipelines read top-to-bottom without visual noise from memory management.
What does not feel like Python
No REPL. In Python I filter a column, look at the head, tweak the filter, repeat. In C I edit the pipeline, run cforge build main, execute, check output, repeat. The loop is tighter than you'd think ~ under a second for incremental builds ~ but it is still a loop, not a conversation. For exploratory data analysis, Python wins.
Error messages are rougher. Pandas tells you KeyError: 'ColumnName'. C tells you your program segfaulted. AddressSanitizer gives you a stack trace pointing to the exact line, which is better than raw C, but it is still not a friendly traceback.
Segfaults happen during development. That is the reality of C. The sanitizer catches most of them before release, but you still spend time in GDB occasionally. The trade is explicit: you pay attention to memory in exchange for deterministic performance and no GC pauses.
The build pipeline as a safety net
The three-stage build is not ceremony ~ it is a net:
- Static analyzer catches null dereferences and buffer overflows at compile time.
- Sanitizer catches heap overflows and use-after-free at runtime during the test execution.
- Release builds with hardening flags once the first two pass.
I have caught bugs in stage 1 or 2 that would have been silent data corruption in Python. The cost is a few seconds of build time. The benefit is confidence that the binary is solid before it ever touches real data.
Would I do it again?
For a known pipeline that runs on a schedule ~ a daily stock screener, a report generator, an ETL job with fixed queries ~ absolutely. You write the pipeline, validate it against the Python reference once, and then the C binary runs in 12 ms instead of 590 ms. For a webapp backend, that is the difference between "please wait" and "instant response."
For exploratory data analysis ~ trying different filters, looking at distributions, prototyping models ~ I would still reach for Pandas or Polars. The REPL workflow is too valuable to give up.
Will I continue using this custom tools combo? Yes. The only thing that could pull me away is a stable Zig 1.0 release. I have reduced Zig usage because of breaking changes in the pre-1.0 ecosystem, but a stable release could change that. Until then, cforge + safe_c.h is my stack for performance and correctness-critical work.
Comments section here
If you enjoyed this post, click the little up arrow chevron on the bottom left of the page to help it rank in Bear's Discovery feed and if you got any questions or anything, please use the comments section.